Modules
The TNL project comprises several domain-specific modules that target mainly computational fluid dynamics. All modules listed below have full multi-GPU support based on the common core library.
TNL-MHFEM
![]()
TNL-MHFEM is an implementation of the Mixed Hybrid Finite Element Method. The numerical scheme is implemented for a PDE system written in the general coefficient with 8 problem-specific coefficients.
The scheme was originally developed for simulating multicomponent flow and transport phenomena in porous media, but it can be used for any problem whose governing equations can be written in a compatible form.
TNL-LBM
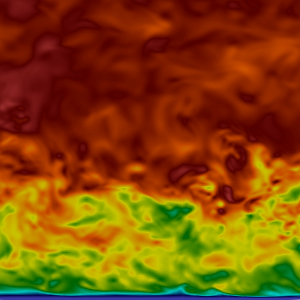
TNL-LBM is an implementation of the Lattice Boltzmann Method. It is a high-performance lattice Boltzmann code for direct numerical simulations (DNS) of turbulent flow. It was verified and validated on multiple problems.
The main features are:
- Modular architecture with pluggable components (collision operators, streaming patterns, boundary conditions, macroscopic quantities, etc). The implemented components include the cumulant collision operator for D3Q27 and the A-A pattern streaming scheme that can significantly reduce memory consumption.
- Optimized data layout on uniform lattice based on the NDArray data structure from TNL.
- Scalable distributed computing based on CUDA-aware MPI and DistributedNDArraySynchronizer from TNL. Good parallel efficiency is ensured by overlapping computation and communication, pipelining and optimized data layout.
- Coupling with the immersed boundary method.
TNL-SPH
![]()
TNL-SPH is an implementation of the Smoothed Particle Hydrodynamics Method. It is a high-performance code for numerical simulations of free surface flow. It is verified an validated on standard SPH benchmarks, comparing the provided results with available experimental data.
The main features are:
- Modular architecture with pluggable components (formulations, schemes, diffusive terms, viscous terms, boundary conditions etc). The implementation includes δ-WCSPH, Boundary Integrals WCSPH and Riemann SPH formulations, and various inlet and outlet boundary conditions.
- Optimized and efficient framework for general particle simulations allowing implementation of other particle methods.
- Distributed multi-GPU computing based on CUDA-aware MPI and 1D domain decomposition using domain overlaps.
Other utility modules provide support for the development of the project, e.g. benchmarks, Python bindings, etc. The complete list of TNL modules can be found on GitLab.